
01

-
Prompt 是他的入职培训手册(告诉他该干什么)。
-
Tools(MCP/Function Calling) 是他的办公文具(笔、纸、电脑)。
-
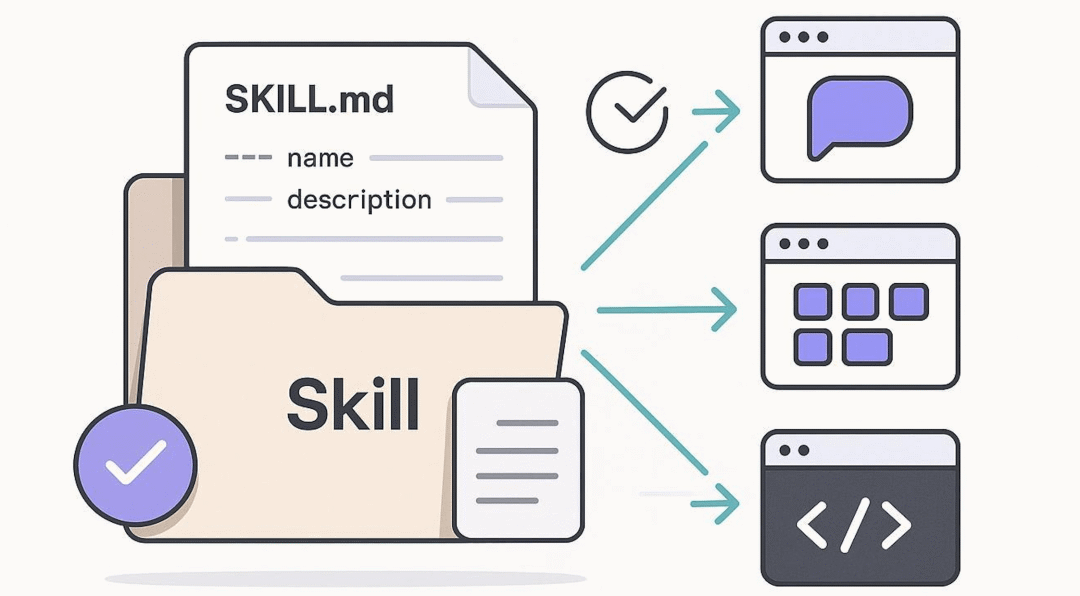
Skill 则是他的职业技能认证(例如:他知道如何操作复杂的财务软件,但只有在需要报销时,他才会去翻阅那本厚厚的操作手册)。

skills/pdf-processing/├── SKILL.md # 主技能文件├── parse_pdf.py # PDF 解析脚本├── forms.md # 表单填写指南(仅在填表任务时加载)└── templates/ # PDF 模板文件 ├── invoice.pdf └── report.pdf
-
当需要执行 PDF 解析时,智能体会运行 parse_pdf.py 脚本
-
当遇到表单填写任务时,才会加载 forms.md 了解详细步骤
-
模板文件只在需要生成特定格式文档时访问
-
无限的知识容量:通过脚本和外部文件,技能可以”携带”远超上下文限制的知识。例如,一个数据分析技能可以附带一个 1GB 的数据文件和一个查询脚本,智能体通过执行脚本来访问数据,而无需将整个数据集加载到上下文中。
-
确定性执行:复杂的计算、数据转换、格式解析等任务交给代码执行,避免了 LLM 生成过程中的不确定性和幻觉问题。
-
每次对话都提供冗长的背景信息和指令。
-
手动复制粘贴数据或 API 格式。
-
反复纠正 AI 的输出格式。
-
标准化流程:将最佳实践固化下来,确保每次执行任务都高质量、格式统一。
-
提升效率:一键调用复杂功能,节省大量提示词输入和调试时间。
-
知识复用:将公司内部知识、产品文档、API 规范等嵌入 Skill,让 Claude 记住并使用它们。
-
能力扩展:通过 API 和工具调用,让 Claude 突破纯文本的限制,与真实世界的系统和数据互动。
02
-
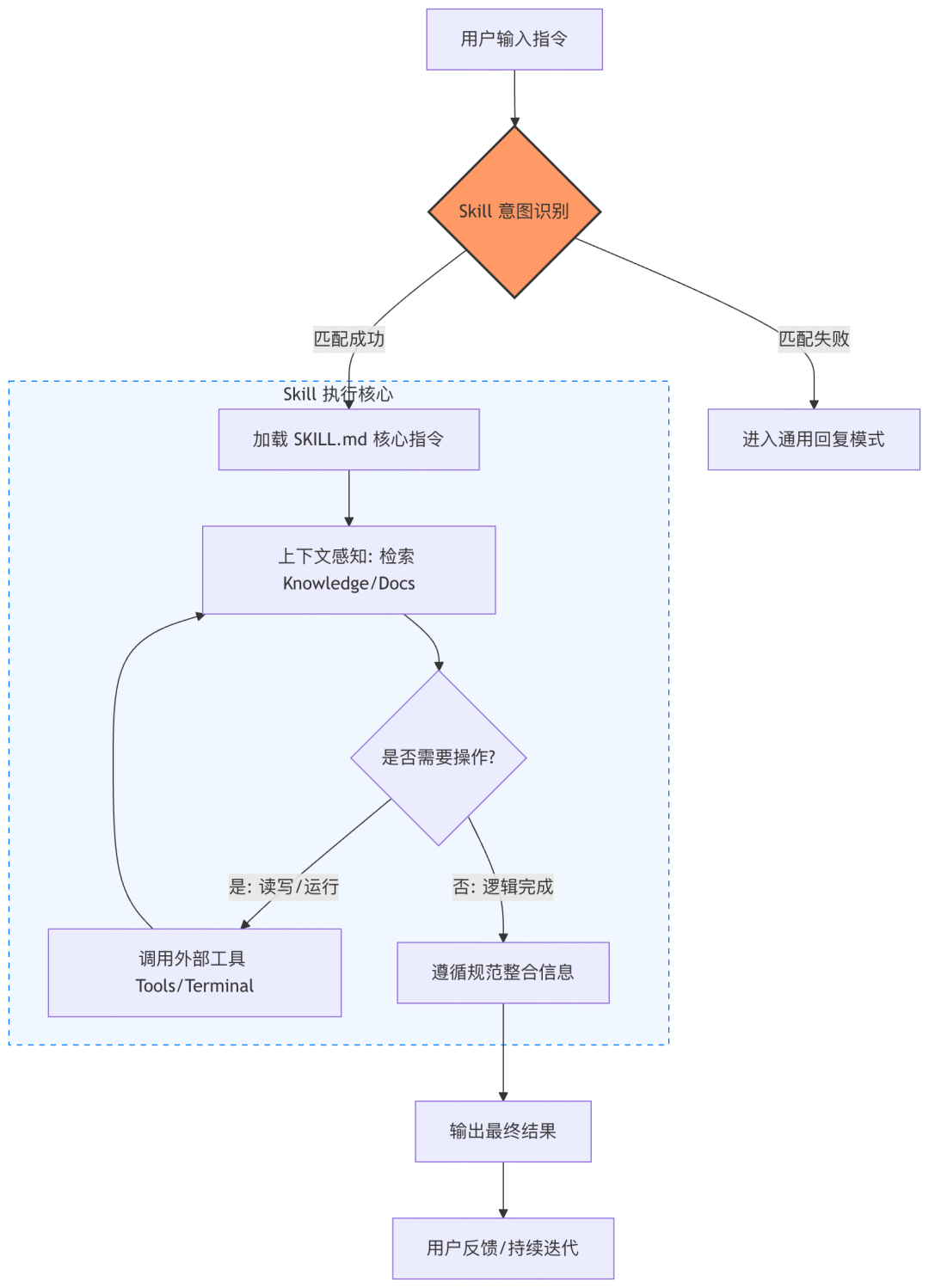
解决上下文爆炸(Context Bloat): 不再需要一次性把所有工具说明塞进 Prompt。
-
实现渐进式披露(Progressive Disclosure): 只有当 Agent 认为需要某个技能时,才会加载该技能的详细文档和子指令。
-
提高成功率: 减少冗余信息的干扰,让模型更专注于当前步骤的推理。
-
复用与共享: 技能可以像 NPM 包或 Python 库一样被定义、存储和跨项目复用。
03
-
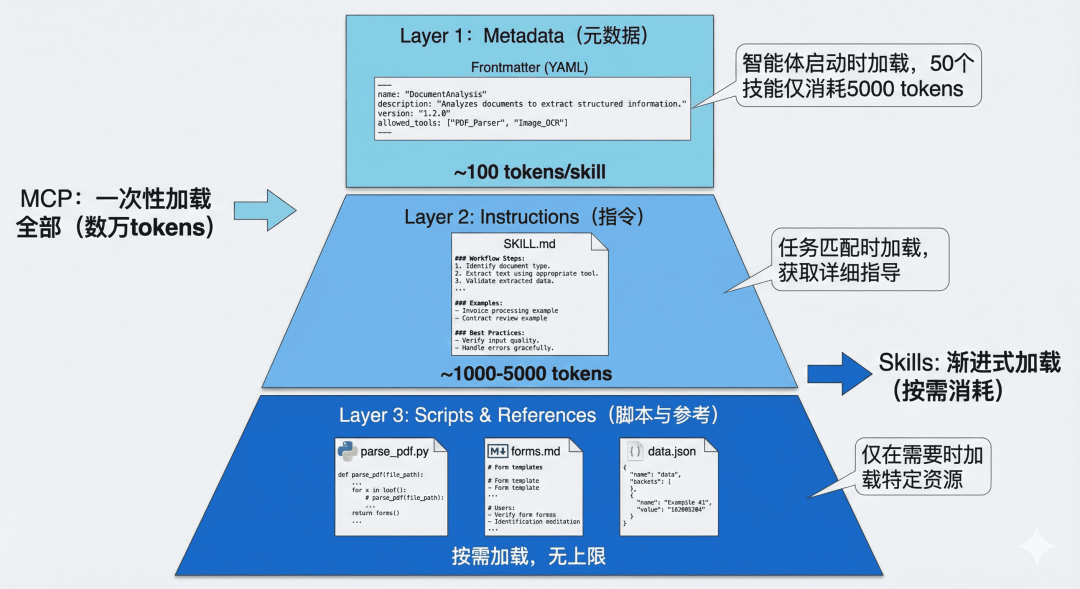
传统 MCP 方式:直接连接一个包含大量工具定义的 MCP 服务器,初始加载消耗 16,000 个 token
-
Skills 包装后:创建一个简单的 Skill 作为”网关”,仅在 Frontmatter 中描述功能,初始消耗仅 500 个 token
-
Prompt 是静态约束: 它定义了 Agent 的性格、语气和全局规则。Prompt 过长会导致模型执行力下降。
-
Skill 是动态能力: 它是原子化的、确定性的功能块。你可以拥有 1000 个 Skill,但每次对话只激活其中的 2 个。
-
MCP 是“通信协议”: 它定义了模型如何连接到外部数据源(如 GitHub, Slack, Postgres)的标准接口。它解决的是“连接”问题。
-
Skill 是“逻辑封装”: 它更偏向于应用层。一个 Skill 内部可以调用多个 MCP 服务,也可以包含复杂的业务逻辑代码。
04
安装这里的skillshttps://github.com/kepano/obsidian-skills

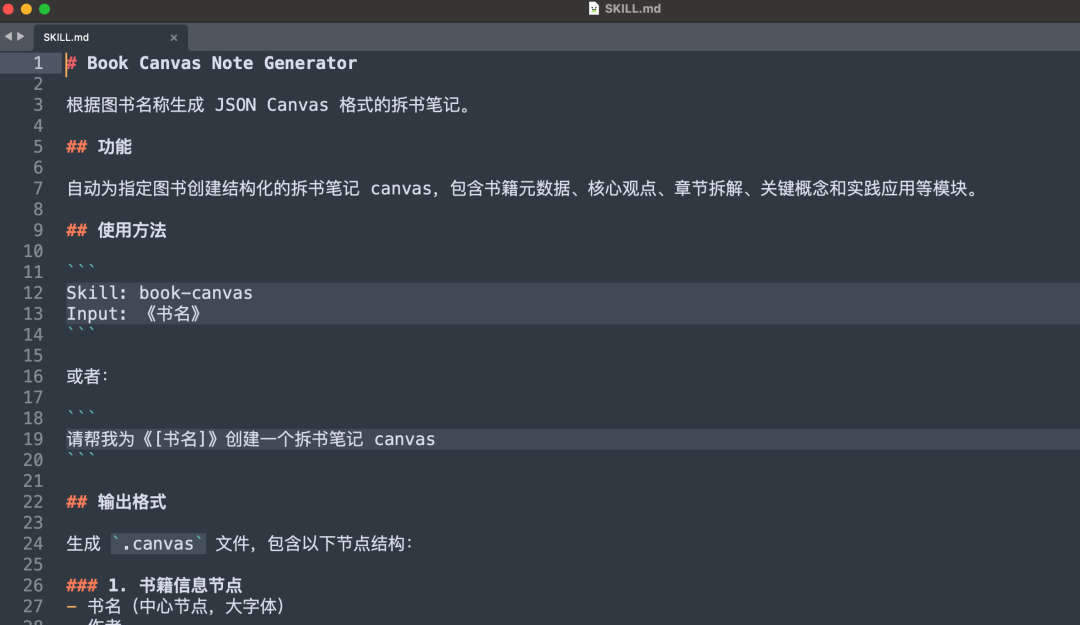
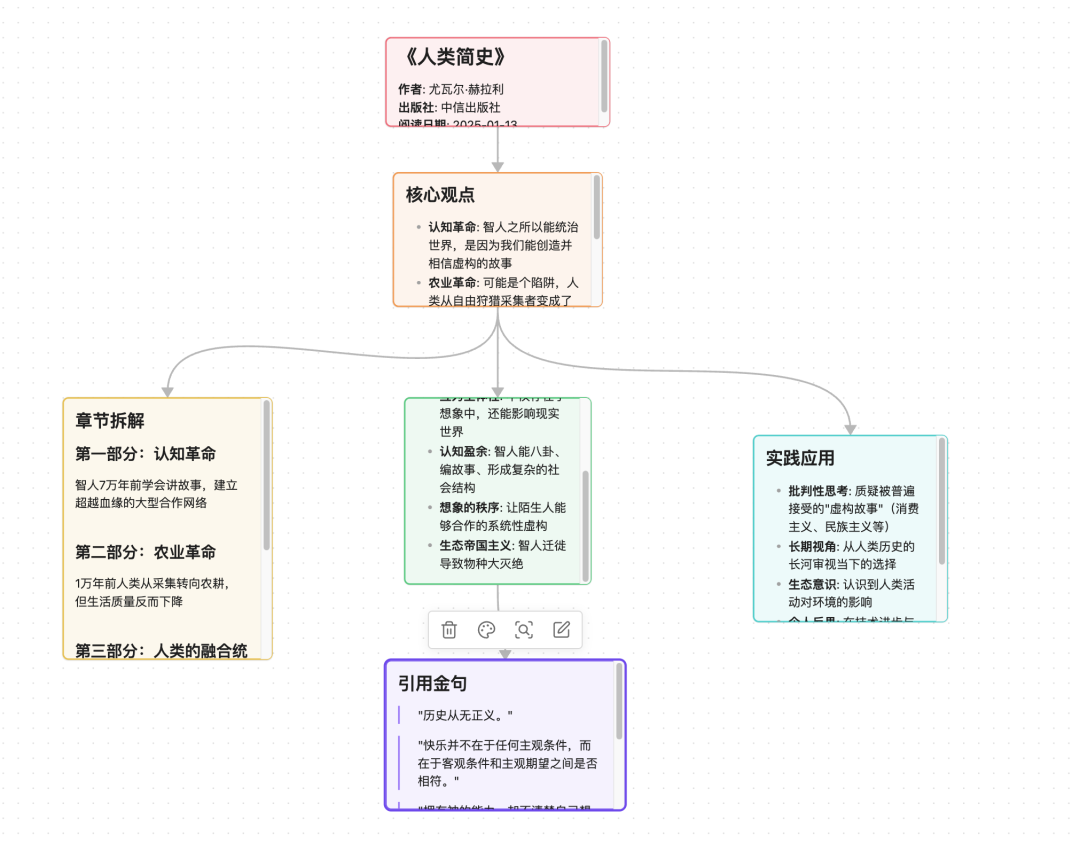
请帮我为《人类简史》创建一个拆书笔记 canvas
05
-
Skill vs Prompt: 别把所有东西都写在 Prompt 里,学会封装 Skill。
-
渐进式披露: 保护你的上下文,只在需要时展示细节。
-
Open Code: 目前体验 Skill 机制的最佳入口。
-
标准化: 尽量遵循类似 MCP 的标准,让你的 Skill 具备跨平台潜力。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。