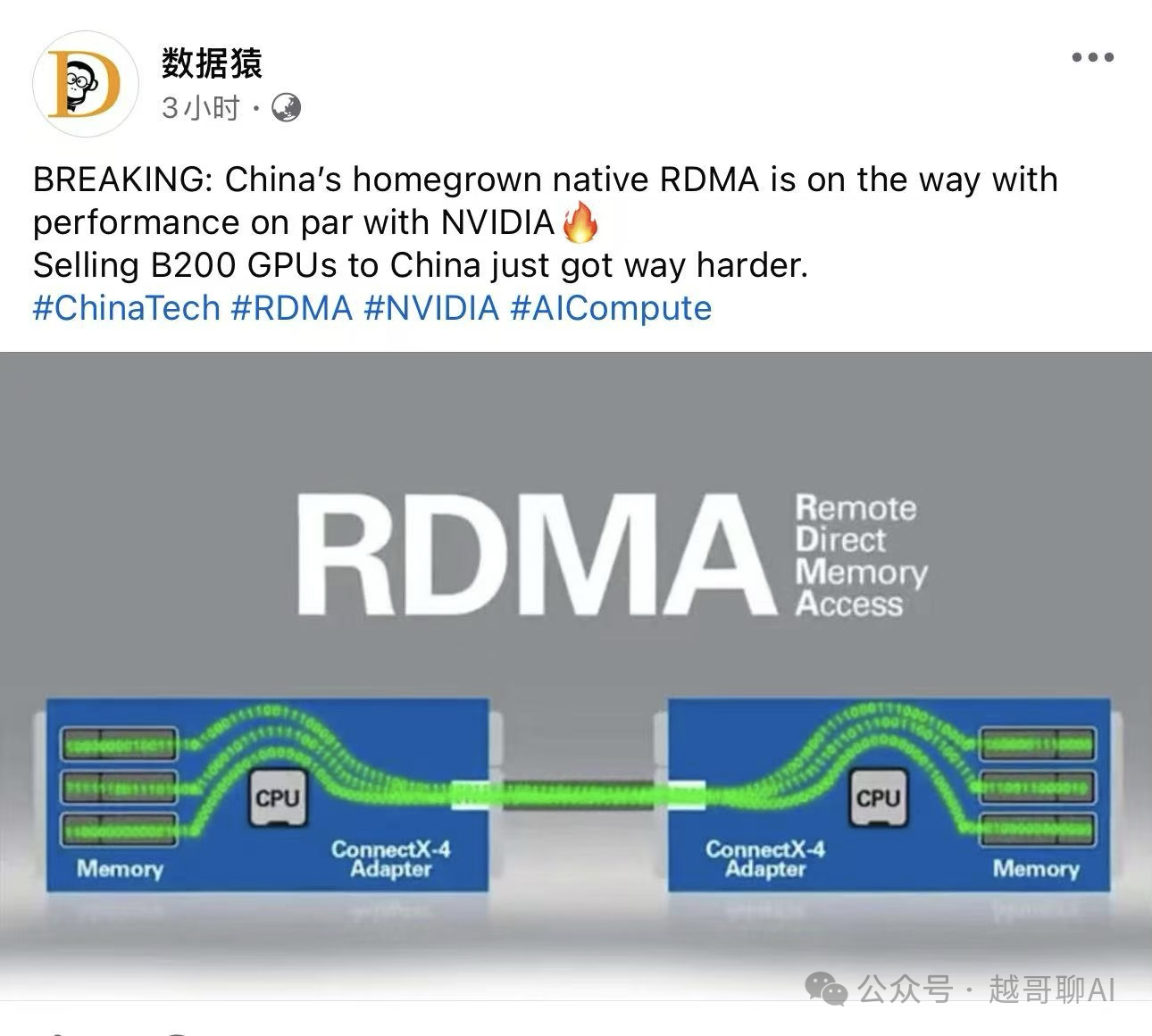
刚收到的外网爆料,值得玩味。<br><br>据相关消息人士透露,国内某头部算力厂商已在原生RDMA技术上取得实质性突破,即将推出对标InfiniBand的高速互联方案。如果属实,这将是国产AI算力进程中一次关键转向——从RoCE的“改良路线”,正式杀入IB的“原生战场”。<br>想要看懂这条新闻,需要理解超大规模智算集群的真实痛点。<br><br>前两天,两会点题的“超大规模智算集群”,落在工程层面,核心就一句话:当集群从千卡向万卡、十万卡狂奔时,网络不再是管道,而是龙骨。大模型训练的通信模式,本质是数万张卡同时做全局同步,任何一次丢包、任何一纳秒抖动,都会被成倍放大,直接折算成算力闲置。<br><br>具体来看,目前的主流方案,各有各的命门。<br><br>RoCE的算盘是在以太网上跑RDMA,成本友好,生态开放,在中小规模集群里足够能打。但它的基因是“尽力而为”,缺乏端到端的无损机制。上到400G高速互联,物理层的先天短板就暴露了——更关键的是,高端交换芯片和网卡芯片的供应,现阶段不完全由我们说了算。<br><br>IB的护城河在于原生无损。它基于信用的流控机制,传输前先确认接收端资源,延迟压到100纳秒级,几乎零丢包。这是为极限场景设计的奢侈体验,代价是封闭生态和英伟达的整合锁死。<br><br>爆料里提到的突破,卡位的正是这个缝隙——原生无损RDMA,兼容主流IB生态,专攻十万卡级集群。这意味着什么?<br><br>第一,国产算力第一次有了万卡级互联的“入场券”。不再依赖RoCE的修修补补,直接对标IB的性能基线,集群规模的天花板被实质性顶开。<br><br>第二,这是对英伟达护城河的精准打击。继CUDA之后,InfiniBand是其在AI算力领域的另一道深壕。国产厂商从网络层切入,打的是算力基建的“底层桩”。<br><br>第三,路线选择的信号已经明确。RoCE的生态位依然存在,但面向超大规模集群,国家队选择的是原生RDMA这条硬骨头路线。<br><br>想到一句评价很到位:“继5G/6G之后,中国在新一代AI基础设施领域的又一重要布局。”这场连接之战,比芯片更隐蔽,却同样决定算力主权的边界。<br><br>国产算力的第二曲线,这次是真的切进了深水区。