
2024年4月29日凌晨,阿里云重磅发布了新一代通义千问模型——Qwen3(千问3),并全系开源!
这一夜,不夸张地说,是中国开源AI历史上的里程碑时刻。
阿里官方表示:
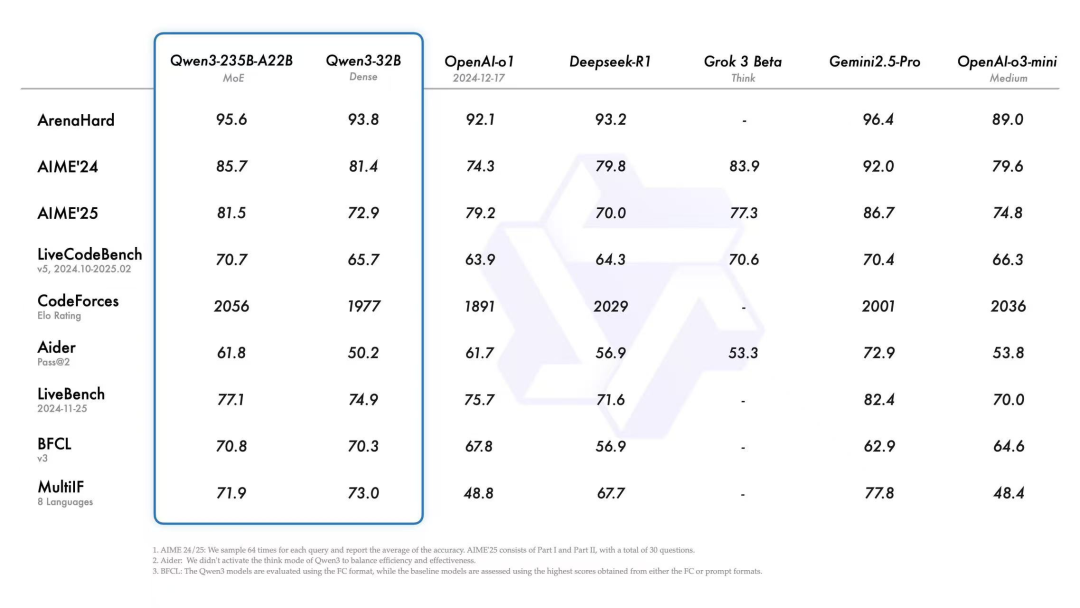
- Qwen3在Chatbot Arena等全球榜单性能全面超越DeepSeek-R1、OpenAI o1等顶级模型,登顶全球开源模型之王。
- 参数量仅为DeepSeek-R1的1/3,推理成本下降到1/3。
- 部署只需4张H20显卡,即可满血上限。
知情人士更直接点名:这是阿里云今年上半年最重磅的发布。

01 | 千问3到底强在哪?
(1) 全球首批混合推理模型之一
Qwen3采用了**混合推理(Hybrid Reasoning)**架构,简单说,模型可以灵活切换:
- 快思考
:简单问题,直接秒回,高效响应。 - 慢思考(Chain of Thought)
:复杂推理问题,逐步推理,严谨作答。
理论上听着简单,但要真正实现,需要在训练策略、数据设计、损失调度上极其深厚的功底。而放眼全球,目前只有极少数模型真正做到。Qwen3,不仅做到了,还开源了。
(2) 参数大,但推理成本小
-
通义千问3旗舰版 Qwen3-235B-A22B,总参数2350亿,激活参数仅22B。 -
相比DeepSeek-R1,参数更少,性能更强,推理、部署成本直接打骨折。
举个简单的数据感受下:
-
部署DeepSeek-R1满血,需要至少12张A100显卡; -
部署Qwen3满血,只需要4张H20!
成本打了1/3,性能反而更好。这,在企业端是真正的降本增效。
Qwen团队在博客文章中写道:
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。
至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。
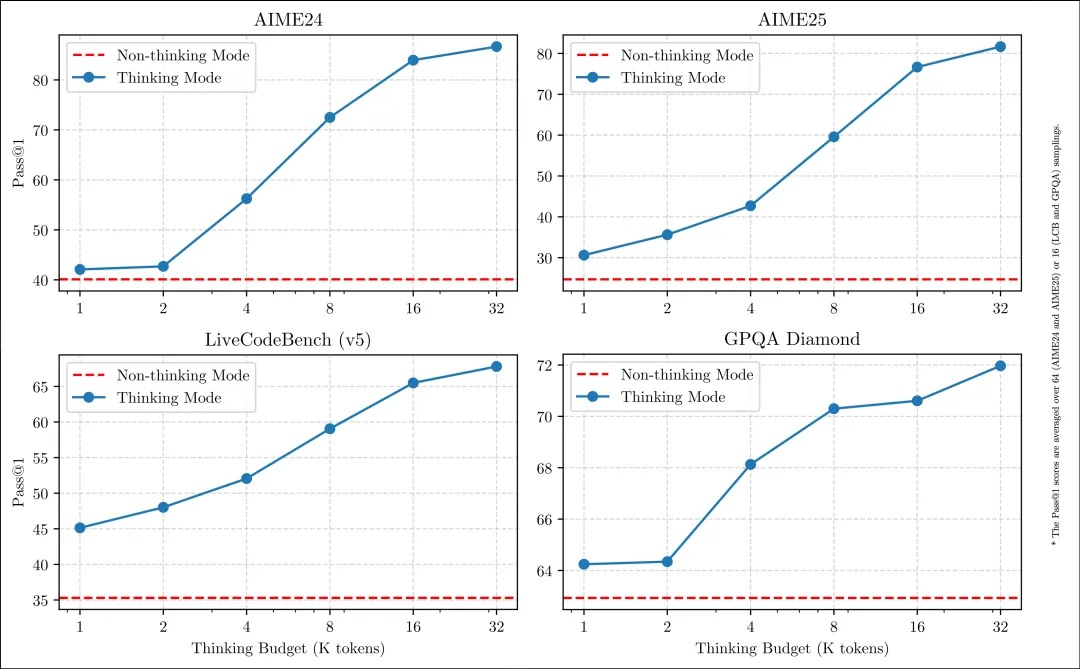
这样的设计让用户能够自行设置“思考成本”,更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
02 | 8款模型全家桶开源
阿里这次不是只放出一个大模型,而是一次性开源了8个版本:
-
稠密Dense模型:0.6B、1.7B、4B、8B、14B、32B -
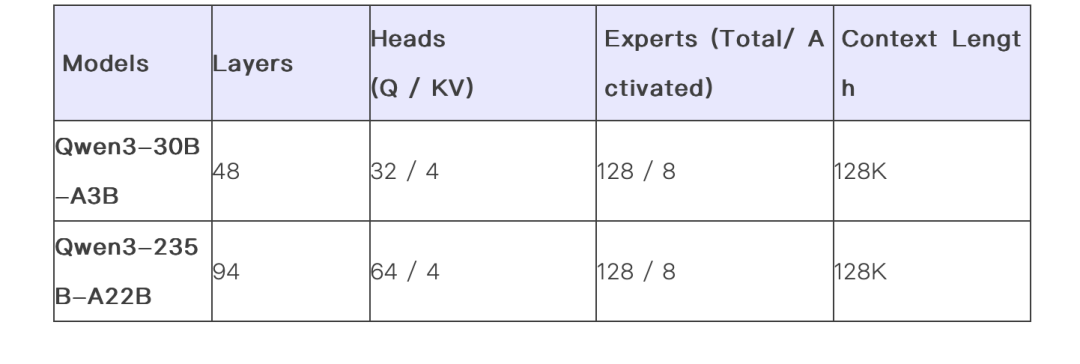
MoE(混合专家)模型:30B(激活3B)、235B(激活22B)
覆盖轻量端到企业级应用全场景,简直是开源界的“性价比之王”。
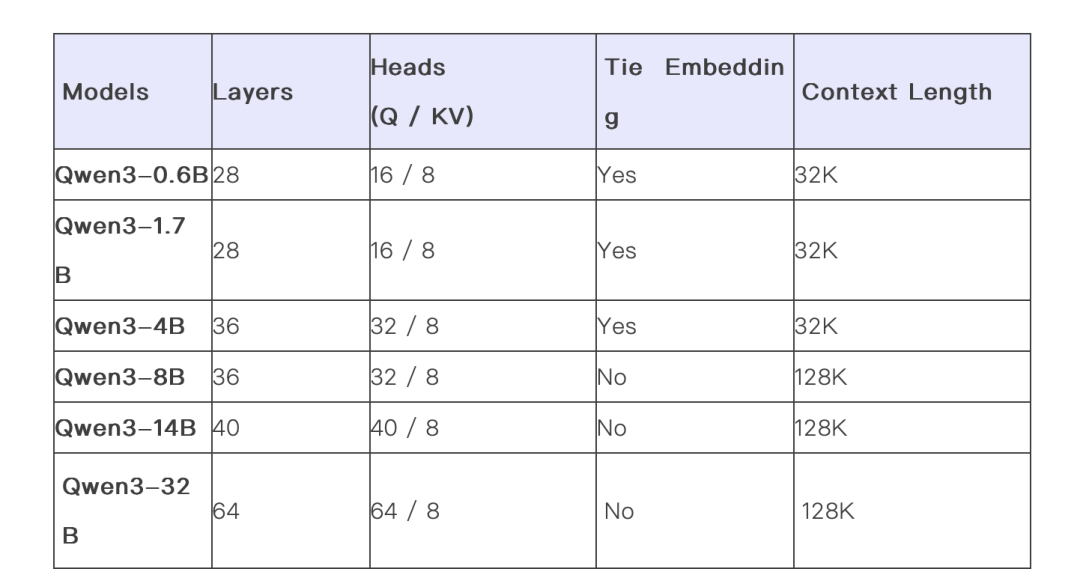
六个Dense模型包括Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B,均在Apache 2.0许可下开源。
多语言、多模态、超长上下文
Qwen3在底层做了系统性升级:
- 支持119种语言和方言
,全球通用。 - 最大上下文32K
,极致长文处理。 - 多模态训练强化
,为未来Agent和智能体打基础。
训练数据量也暴增:
-
Qwen2.5用的是18T tokens, -
Qwen3直接扩到36T tokens!
内容不仅来自网页,还有大量PDF提取数据、数学、编程、推理专项数据合成,训练过程分四大阶段,强化推理、指令理解和Agent能力。
阿里巴巴表示,Qwen3系列支持119种语言,并基于近36万亿个token(标记)进行训练,使用的数据量是Qwen2.5的两倍。Token是模型处理的基本数据单元,约100万个token相当于75万英文单词。阿里巴巴称,Qwen3的训练数据包括教材、问答对、代码片段等多种内容。
据介绍,Qwen3预训练过程分为三个阶段。在第一阶段(S1),模型在超过30万亿个token上进行了预训练,上下文长度为4K token。这一阶段为模型提供了基本的语言技能和通用知识。
在第二阶段(S2),训练则通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的5万亿个token上进行了预训练。在最后阶段则使用高质量的长上下文数据将上下文长度扩展到32K token,确保模型能够有效地处理更长的输入。
03 | 为什么说“只有领先者才敢开源”?
真正的技术进步,不是闭源垄断,而是开放共享。
今天想给这句话加个补充——
“开源,从来是技术实力的试金石。只有领先者,才敢开源。”
如果自家模型不够强,不够稳定,不够领先,开源就是裸奔,风险极大。
而像今天阿里通义千问3这种级别,是真正“自己有货,才敢亮剑”的体现。
过去一年,我几乎体验了所有主流国产大模型,也对接过多个AI项目,从应用到底层训练都有实操。
这次Qwen3发布,我个人总结了几个非常重要的信号:
- 中美顶级模型差距正在迅速缩小
Chatbot Arena的实测数据已经很直观了。国产模型在基础能力、推理、多模态理解等方面,已经逼近甚至超越了OpenAI o1级别。 - 国产AI应用生态的底盘正在夯实
有了像Qwen3这样的底座,未来做AI Agent、做垂直行业大模型,会更便宜、更快、更高效。 - AI从训练模型时代,转向训练Agent时代
未来不是谁调得出更大的参数模型,而是谁能基于这些基础大模型,做出真正可用的智能体(Agent)。 - 部署门槛大降,机会正在涌现
以前用AI都需要大几百万元堆硬件,现在只要几张H20显卡,一般中型公司都能搞得起。
这波,真正到了全民AI创业的时候了。
04 | 最后
今天,我们见证了阿里云的又一次壮举。
但更重要的是,我们见证了中国AI开源力量的全面崛起。
记住,开源不是落后者自救,是领先者亮剑。
未来,国产大模型的胜负手,一定还在路上。
但今晚,属于阿里,也属于所有愿意相信技术力量的人。